L'Encyclopedia Britannica vient de poursuivre OpenAI pour ChatGPT – voici pourquoi la formation en IA est (encore) critiquée
0
Suivez-nous
L'Encyclopaedia Britannica – l'un des éditeurs de référence les plus anciens et les plus respectés au monde – a intenté une action en justice contre OpenAI, accusant l'entreprise d'utiliser son matériel protégé par le droit d'auteur pour former des systèmes d'IA comme ChatGPT sans autorisation.
Selon un rapport de Reuters, le procès a été déposé devant le tribunal fédéral de Manhattan et inclut également l'éditeur de dictionnaires Merriam-Webster.
L'article continue ci-dessous
Pourquoi Britannica poursuit OpenAI

Regarder dessus
Dans la plainte, Britannica allègue qu'OpenAI a utilisé près de 100 000 articles de son encyclopédie sans licence pour le matériel. Ces articles font partie de la base de données de référence de haute qualité que Britannica a construite au fil des décennies avec des historiens, des chercheurs et des experts en la matière.
Le procès fait valoir que la formation de systèmes d’IA sur ce matériel sans autorisation équivaut à une violation du droit d’auteur.
Britannica affirme également que les outils d'IA comme ChatGPT peuvent parfois générer des réponses qui ressemblent à des passages de l'encyclopédie, ce qui, selon elle, pourrait nuire à son activité en donnant des informations aux utilisateurs sans les envoyer à la source d'origine.
Dans le dossier, les sociétés auraient demandé au tribunal des dommages financiers et une ordonnance empêchant OpenAI d'utiliser leur contenu dans de futures formations.
La plus grande bataille autour des données d’entraînement de l’IA

L’affaire fait partie d’une vague beaucoup plus large de poursuites visant les entreprises d’IA au sujet des données utilisées pour former de grands modèles de langage.
Les éditeurs, les auteurs et les médias affirment de plus en plus que leurs travaux ont été utilisés pour entraîner des systèmes d’IA sans consentement.
L’une des affaires les plus surveillées a été déposée par la New York Times Company, qui a poursuivi OpenAI en justice pour des allégations selon lesquelles ses articles auraient été utilisés pour entraîner des modèles d’IA.
Des auteurs, dont George RR Martin et John Grisham, ont également participé à des actions en justice liées aux données d'entraînement à l'IA.
Dans le même temps, le débat s’est étendu au-delà des éditeurs pour inclure les utilisateurs quotidiens de l’IA. De nombreuses entreprises d’IA permettent aux utilisateurs de refuser que leurs conversations soient utilisées pour améliorer les futurs modèles, reflétant les inquiétudes croissantes quant à la manière dont les données des utilisateurs peuvent contribuer aux systèmes de formation.
Au cœur de ces poursuites se trouve une question fondamentale que les tribunaux doivent encore trancher : la formation de l’IA sur du matériel protégé par le droit d’auteur est-elle considérée comme un usage équitable – ou une violation du droit d’auteur ?
La réponse pourrait déterminer comment les futurs modèles d’IA seront développés et si les entreprises devront obtenir des licences pour des quantités massives de données de formation.
Comment refuser que vos conversations ChatGPT soient utilisées pour la formation
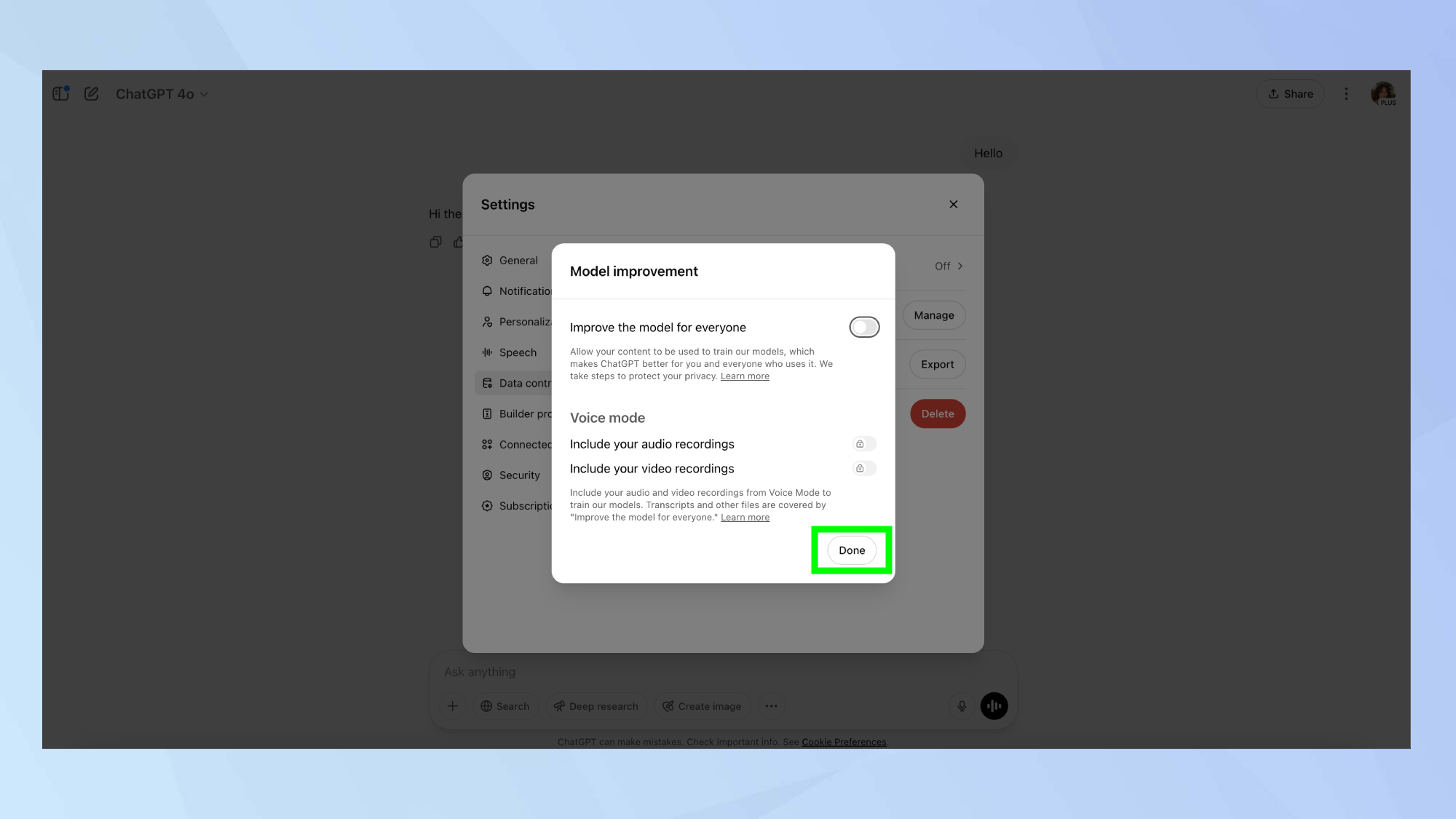
Si vous êtes préoccupé par la manière dont vos conversations pourraient être utilisées pour améliorer les modèles d'IA, OpenAI permet aux utilisateurs de désactiver la formation en fonction de leurs discussions.
Pour ce faire :
- Connectez-vous à ChatGPT
- Cliquez sur votre icône de profil
- Aller à Paramètres
- Robinet Contrôles des données
- Éteindre « Améliorer le modèle pour tous »
Une fois désactivée, OpenAI indique que vos conversations ne seront pas utilisées pour entraîner ou améliorer les futures versions du modèle, bien qu'elles puissent toujours être stockées temporairement pour des raisons de sécurité et de surveillance des abus.
De nombreuses entreprises d’IA ont introduit des contrôles similaires alors que les inquiétudes grandissent quant à la manière dont les données des utilisateurs, les articles publiés et autres contenus en ligne sont utilisés pour former des systèmes d’IA générative.
Réflexions finales
Le procès de Britannica se distingue par le type de contenu impliqué. Contrairement aux publications sur les réseaux sociaux ou aux pages Web supprimées, les articles de Britannica sont des documents de référence soigneusement étudiés qui ont longtemps été considérés comme l'une des sources d'informations factuelles les plus fiables.
Cela pourrait rendre l’affaire particulièrement importante alors que les tribunaux tentent de définir les limites de la formation en IA. Si les tribunaux décident finalement que la formation de l’IA sur du matériel de référence protégé par le droit d’auteur nécessite une autorisation ou une licence, cela pourrait remodeler l’économie de la construction de systèmes d’IA.
Cela pourrait également influencer la manière dont les entreprises d’IA gèrent la transparence des données de formation, les accords de licence et le contrôle des utilisateurs sur la manière dont leurs données sont utilisées pour améliorer les systèmes d’IA.
Pour l’instant, l’affaire ne fait que commencer. Mais cela ajoute simplement un autre défi juridique de grande envergure à la lutte d'OpenAI pour remporter la course à l'IA.



